
Sometimes the most beautiful cost optimizations break production in ways you never expect.
The Beginning: A Simple Optimization
We had a web application running on Amazon ECS with AWS Fargate. The app processed background jobs: taking files, generating archives, and returning results to users asynchronously.
Then we noticed: EFS costs were much higher than expected.
After checking billing, the culprit was clear: read/write operations, not storage size. Most operations were temporary files during archive generation.
The fix seemed obvious: move transient workload from EFS to container /tmp (ephemeral storage).
Results:
- ✅ ~70% cost reduction
- ✅ No network storage dependency
- ✅ Cleaner architecture
We deployed. Production started acting strange.
What We Didn’t See
The async flow:
| |
The critical detail: Background commands executed inside the same container handling HTTP traffic.
No dedicated worker. No isolation. Just “another process” in the web task.
What went wrong:
| |
The cost optimization worked. The architecture didn’t.
The Real Problems
Problem 1: Hidden Coupling
Async logic inside web containers meant shared resources:
| Resource | Impact |
|---|---|
| CPU | Jobs starve web requests |
| Memory | OOM kills affect both |
| Storage | Ephemeral fills, web fails |
| Lifecycle | Deploy kills jobs |
Problem 2: No True Decoupling
No durable queue. No guaranteed delivery. No retry strategy. No job ownership.
Just direct triggering. It looked asynchronous but wasn’t architecturally decoupled.
Problem 3: Autoscaling Chaos
When autoscaling or deployments terminated tasks, running jobs disappeared. No state. No retry. No visibility.
Why Not Lambda or Batch?
| Solution | Why Not? |
|---|---|
| Lambda | • 6 MB response limit • Storage constraints • Cold starts • Execution time limits |
| Batch | • 2-3 min startup latency • Image pull overhead • Overkill for 1-5 sec tasks • Cost inefficient for high-frequency jobs |
We needed: Fast startup, isolated from web traffic, scalable, durable, cost-aware.
The Solution: Dedicated Worker Architecture
High-Level Architecture:
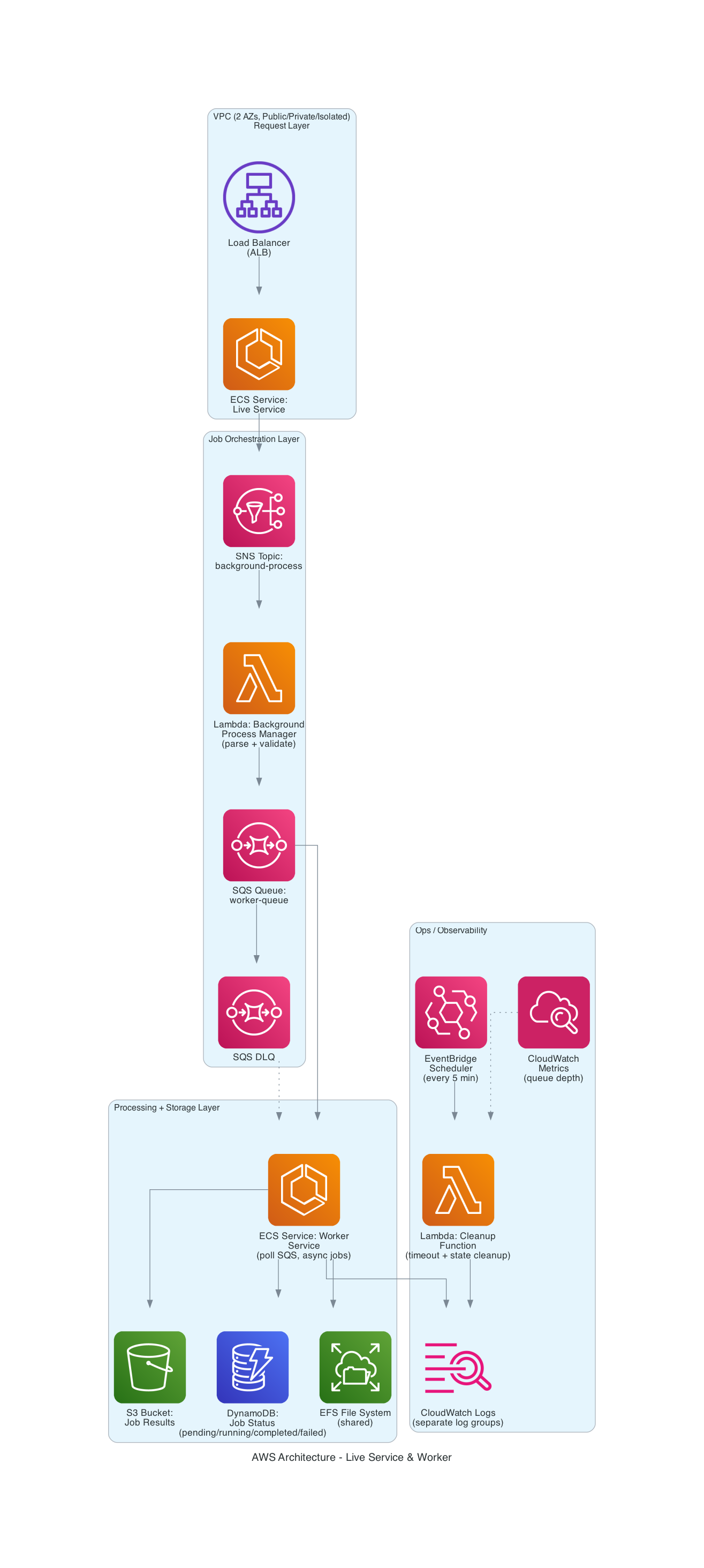
Flow:
| |
Queue-Based Decoupling
Introduced Amazon SQS for durable job management:
✓ Guaranteed delivery
✓ Automatic retries
✓ Dead-letter queue for failures
✓ Back-pressure control
Dedicated Worker Service
Separate ECS service with:
| Feature | Benefit |
|---|---|
| Independent scaling | 1-10 tasks based on queue depth |
| Isolated resources | CPU/memory tuned for jobs |
| Separate lifecycle | Deployments don’t kill jobs |
| Dedicated logs | Clear observability |
State Management
| Component | Purpose |
|---|---|
| DynamoDB | Job tracking & status |
| S3 | Results storage |
| EFS | Only where necessary |
AWS Well-Architected Alignment
| Pillar | Implementation |
|---|---|
| Reliability | Durable queue, DLQ, retries, graceful termination |
| Performance | Auto-scaling based on queue depth, independent tuning |
| Cost | Ephemeral storage where appropriate, no over-provisioning |
| Operations | Infrastructure as Code, dedicated monitoring, clear ownership |
| Security | Isolated IAM roles, least privilege, private networking |
Key Takeaways
The lesson: The solution wasn’t just separation — it was architectural decoupling.
Sometimes a 2-second background task requires a properly designed distributed system.
Why? Production doesn’t fail on obvious parts. It fails on invisible assumptions.
Before:
| |
After:
| |
The difference between “it works” and “it survives production”:
Don’t just make systems asynchronous. Make them decoupled.